
助力端侧生成式AI 高通NPU+异构计算增强AI体验
3月6日,高通发布了最新白皮书《通过NPU和异构计算开启终端侧生成式AI》,深入阐述了NPU与异构计算,对端侧生成式AI使用的重要性。
3月6日,高通发布了最新白皮书《通过NPU和异构计算开启终端侧生成式AI》,深入阐述了NPU与异构计算,对端侧生成式AI使用的重要性。与此同时,高通也举办了技术沟通会,对白皮书进行了解读,并申明高通如何靠技术推动终端侧生成式AI开发和应用。

异构计算与NPU
高通其实在很早时候就在强调异构计算的概念,只不过当时还没有NPU入局,而是通过CPU、GPU、DSP等不同核心进行协作,发挥各处理单元的运算优势,来加快处理速度。
异构计算能够充分发挥硬件优势,比如CPU就很擅长顺序控制,非常适用于需要低时延的应用场景,在相对较小的神经网络模型(CNN),或一些特定的大语言模型(LLM),就很适合CPU来进行运算。而GPU主要擅长面向高精度格式的并行处理,比如对画质要求非常高的图像以及视频处理。
而近些年十分热门的NPU,则是专门为AI所打造的。AI运算上的主要负载是由标量、向量和张量的数学运算,虽说“万能的”CPU也能对此进行处理,不过处理速度和功耗方面都不理想。NPU正是针对AI运算所打造的新处理单元,高通在2015年推出的第一代AI引擎,在Hexagon NPU集成了标量和向量运算核心,之后又加入了张量运算核心,从而极大加快了AI处理速度,并使AI运算处理的功耗大幅度降低。
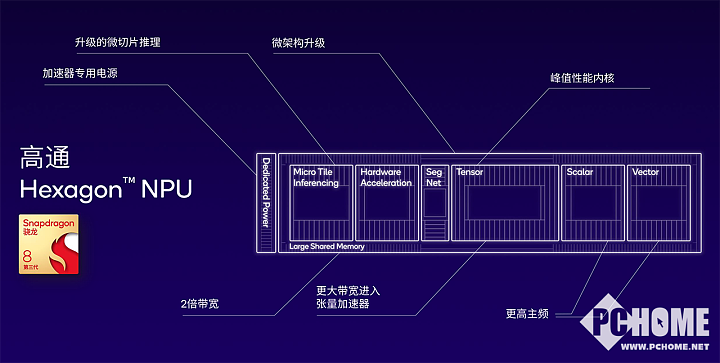
目前,Hexagon NPU集成了不同的组件,在第三代骁龙8中,张量运算核心的峰值性能大幅提升了98%,标量和向量运算性能也得到了提升。集成了用于图像处理的分割网络模块,还增加了非线性功能的硬件加速能力。
凭借微切片推理技术,可以把一个神经网络层分割成多个小切片,最多提供十层深度上进行融合,而市面上的其他AI引擎则必须要逐层进行推理。此外,Hexagon NPU还集成了大共享内存,提供加速器专用电源传输轨道,也为大共享内存带来更大的带宽。

对于端侧生成式AI来说,异构计算是必要条件。高通在MWC 2024中展示的Stable Diffusion快速生成图片,就是完全依靠端侧算力,它需要NPU进行推理,需要GPU进行图像渲染,也正是在异构运算的帮助下,才能在10秒不到的时间里完成图片生成,并且能够保持低功耗,保持手机终端的高电池续航。

虚拟化身AI助手同样需要异构运算处理,其需要运行ASR模型将语音转为文本,然后通过大语言模型生成文本回复,再通过模型将文本转为语音。之后使用融合变形动画(Blendshape)技术让语音与虚拟化身的嘴型匹配,实现音话同步。此后通过GPU进行虚拟化身渲染。最终通过协同使用高通AI引擎上所有的多样化处理模块,实现出色的交互体验。
显然,Hexagon NPU作为专为AI打造的处理单元,在端侧生成式AI的推进上必不可少,传统的CPU、GPU支持同样不可或缺。高通骁龙移动平台在CPU方面,会在今年启用自研的Oryon CPU,相比此前的ARM公版架构,Oryon无疑有着更大的自主性,并且在后续的优化上也更为轻松。Adreno GPU是高通自主打造的,不仅性能表现出色,而且能效上也表现更好。各处理单元相辅相成,构建出的异构运算能力,正是生成式AI所需要的,也是端侧生成式AI的更佳解决方案。
全面技术支持 加速生成式AI应用
高通对生成式AI应用的推动是全方面的,比如在至关重要的内存方面,就在软硬件上均有技术支持。在端侧部署大语言模型,在内存速度和内存容量上都有很高要求。新款的第三代骁龙8移动平台,支持LPDDR5X内存,运行频率高达4.8GHz,能够高速运行大语言模型。
对于大模型吃内存的问题,高通在NPU上提供了4位整数模型的原生支持,其所占用的内存要比16位整数模型小得多。在高通AI引擎中集成的模型压缩等技术,则能够让大模型可以在有限的内存空间顺利运行。

在AI应用的市场推进上,高通AI Hub能够让开发者快速将AI大模型部署到应用中,使开发效率倍增。高通AI Hub目前已经有近80个AI模型的模型库,既有生成式AI模型,也有CNN等传统AI模型,开发者选择想要使用的模型,就可以看到该模型可以在什么平台上运行,选择平台后就能直接生成二进制插件,在应用中插入即可实现相应的AI能力。
利用高通AI软件栈,开发者可在高通硬件上创建、优化和部署AI应用,一次编写即可实现在不同产品和细分领域采用高通芯片组解决方案进行部署。




 +61
+61 +86
+86 +886
+886 +852
+852 +853
+853 +64
+64


